Система поддержки принятия врачебных решений с использованием технологий искусственного интеллекта для контроля (оценки) качества лечения в соответствии с утвержденными клиническими рекомендациями (СППВР ИИ)
СППВР ИИ: информационно-аналитическая система обработки и представления данных в сфере здравоохранения с использованием технологий искусственного интеллекта
Основной класс программного обеспечения по классификатору программного обеспечения, утвержденному приказом от 22.09.2020 № 486: 04.06 Средства разработки программного обеспечения на основе нейротехнологий и искусственного интеллекта.
Программа «СППВР ИИ» предназначена для обработки и анализа структурированных и неструктурированных массивов данных и обучения моделей искусственного интеллекта для задач создания баз знаний, аналитике в медицине.
Базовым сервисом «СППВР ИИ» является сервис унифицированной оцифровки медицинских документов – генерации цифрового профиля документов на основе использования Базы медицинских знаний (БМЗ), технологий обработки естественного языка.
В составе программного комплекса «СППВР ИИ» используется программный продукт «Модуль визуализации DataMonitor», относящийся к классу программного обеспечения «Системы сбора, хранения, обработки, анализа, моделирования и визуализации массивов данных». Приказом Минкомсвязи России от 25.07.2019 № 412 зарегистрирован в Едином реестре российских программ для электронных вычислительных машин и баз данных (регистрационная запись от 26.07.2019 № 5609). https://reestr.digital.gov.ru/reestr/306959/ .
НАПРАВЛЕНИЯ ПРОЕКТА
- Информационные сервисы поддержки принятия решения врачом;
- Телемедицинские системы и цифровые платформы для медицинских сервисов;
- Информационные технологии и решения для обучения специалистов здравоохранения.
Краткое резюме проекта, имеющиеся наработки
- Создана База медицинских знаний (Knowledge Base) на основе обработки 20 млн медицинских статей из Pubmed и интеграции российских и международных справочников и классификаторов.
- Разработаны сервисы выделения объектов и связей из медицинских мультиязычных текстов.
- Разработаны сервисы оцифровки медицинских текстов объектами БМЗ.
- Создан семантический корпоративный поисковик медицинских текстов.
ПРОБЛЕМА. ТЕХНОЛОГИЧЕСКИЕ БАРЬЕРЫ
Проблема, на решение которой направлен проект
Опсание проблемы:
- До 80% клинически-значимой информации хранится в ЭМК в неструктурированных текстовых
записях.
- Врачебные осмотры
- Лабораторные исследования
- Инструментальные исследования
- Прошлые эпизоды, связанные с заболеваниями
- Другие данные пациента
- Врачи перегружены. Времени на прием и внимательный анализ данных пациента не хватает (12 минут на прием), поток пациентов большой.
- Неравномерность профессионального уровня врачей – молодые специалисты опасаются ставить диагнозы.
Технологические барьеры
В России с развитием проектов ЕГИСЗ и его составляющей СЭМД, стандартизуется (HL7 CDA R2) обмен медицинскими данными ЭМК (EHR) по системе здравоохранения:
- горизонтальный обмен: ЛПУ – ЛПУ;
- вертикальный обмен: ЛПУ – страховые медицинские организации – ФОМС – органы здравоохранения – органы статистики.
Регионы начали серию тендеров на модернизацию стандартами обмена с ВИМИС эксплуатируемых в ЛПУ медицинских информационных систем.
Стандарт обмена HL7 CDA R2 подразумевает наличие, как полей, содержащий данные (пол, возраст, вес и т.п.), так и полей, содержащих текстовую информацию, – «Общие сведения о госпитализации», «Анамнез заболевания», «Состояние при поступлении» методы диагностики, лечения и т.д.
Передача информации между субъектами здравоохранения в виде совокупностиданных (не текстовых блоков) могло бы повысить эффективность оказания медицинской помощи.
Однако, все функционирующие в России медицинские информационные системы (МИС) кодируют и хранят в своих базах «холеру» и «ОРВИ» со своими локальными идентификаторами. Общей задачей «интеллектуализации» функций сопровождения лечебно-диагностического процесса является создание формализованного описания медицинских текстов. Формализация означает, что всем медицинским понятиям и сущностям в медицинских текстах должны быть присвоены идентификаторы из единого централизованного источника.
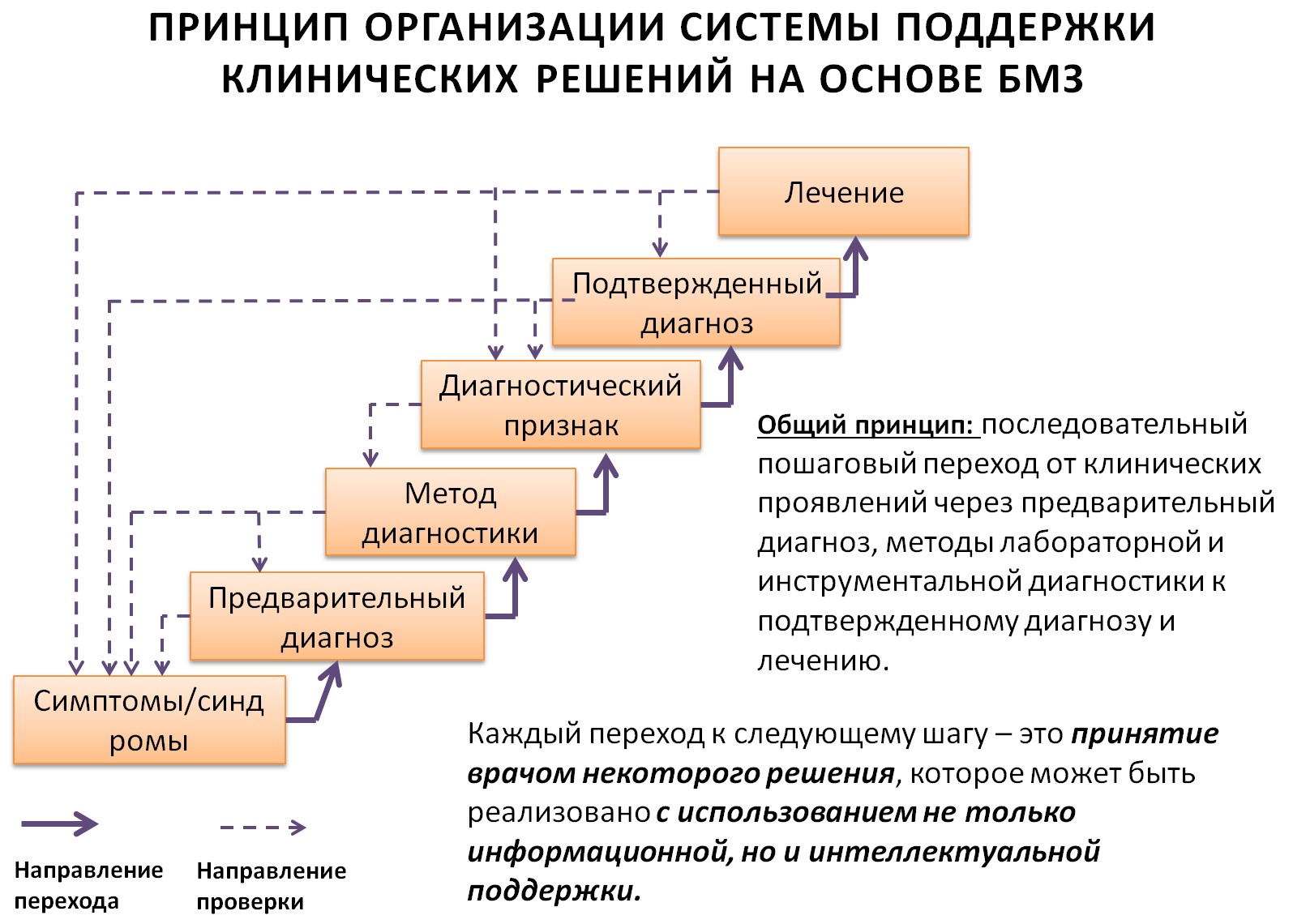
Выделенные из текстов протоколов лечения, выписных эпикризов, оцифрованные понятия и сущности могут быть использованы в качестве входных данных в существующие компьютерные алгоритмы, реализующие функции систем поддержки принятия врачебных решений: диагностики состояний пациентов, алгоритмы назначения лечения, статистического и экономического анализа. Выделенные понятия и сущности должны быть синхронизированы с кодами российских и международных справочников.
Выделенные из опубликованных на сайте Минздрава и из общепризнанных текстов международных клинических рекомендаций понятия и сущности могут быть использованы для проверки качества медицинской помощи на соответствие принятым стандартам.
Также примером может служить востребованность сервиса разметки выписных эпикризов из стационара кодами МКБ-10. В структуре здравоохранения России назначение кодов МКБ-10 сегодня производят вручную на уровнях:
- ЛПУ, скорая помощь – коды МКБ-10 являются основой для формирования счетов на оплату по тарифам ОМС/ДМС, статистической отчетности.
- Страховые медицинские организации – экспертиза счетов по оплате ОМС/ДМС от ЛПУ.
- Территориальные фонды ОМС – экспертиза счетов от страховых компаний по оплате ОМС.
- Минздрав и региональные департаменты здравоохранения – статистический учет.
- Медицинские университеты (53) и исследовательские центры.
Оцифрованные в медицинских документах понятия и сущности могут быть также использованы для реализации функций категоризации, поиска и фильтрации медицинской литературы в больших электронных хранилищах документов, - семантических информационно-поисковых систем.
Большое количество стартапов и ИТ-компаний разрабатывающих решения на основе искусственного интеллекта сконцентрировались на применениях технологий интеллектуальной обработки изображений. Одной из целей этих решений является автоматическая генерация клинических заключений (текстовых) по выявленным на изображениях патологиям. При интеграции этих решений на основе ИИ с существующими МИС, из текстов этих документов должны быть выделены медицинские сущности для загрузки в базу данных МИС.
К сожалению, ни в одном проекте до сих пор не реализовано внедрение функций, которыми бы единообразно кодировались в медицинских текстах все признаки, симптомы и синдромы, результаты лабораторной диагностики, диагнозы, характеризующие состояние пациента, назначения и рекомендации, – в соответствии с принятыми российскими и международными классификаторами и справочниками.
РЕШЕНИЕ
Проблема повышения эффективности информационного обмена по принятым Минздравом РФ стандартам ЕГИСЗ и СЭМД:
- По данным статистики, каждый россиянин в среднем посещает медицинские организации примерно восемь раз в год. Каждое обращение фиксируется в эксплуатируемой в ЛПУ в медицинской информационной системе (МИС) в ЭМК пациента.
- При обмене информацией о пациенте с другими субъектами системы здравоохранения принятый Минздравом РФ XML-протокол стандарта обмена электронными документами – «HL7 CDA R2» может быть дополнен оцифрованными медицинскими сущностями из текстов ЭМК.
- Сервис разметки позволяет генерировать:
- Цифровые профили клинических случаев;
- Цифровые профили пациента;
- Цифровые профили заболеваний / состояний / симптомов / синдромов / рекомендованных Минздравом РФ протоколов лечения;
- Цифровые профили лечебно-профилактических учреждений (необходимы статистике).
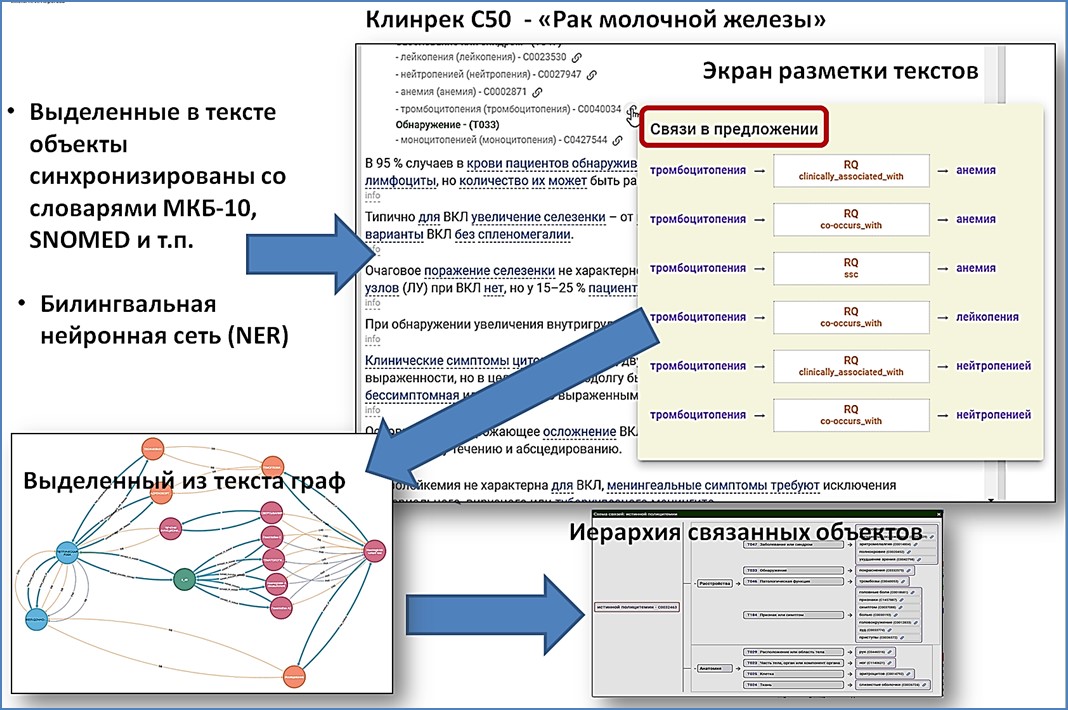
Созданы пользовательские интерфейсы позволяющие размечать принятые Минздравом РФ клинические рекомендации и представлять эти текстовые документы в виде xml-файлов со структурой «Заболевания – Клинические признаки – Сопутствующие заболевания – Методы диагностики – Методы лечения – Методы профилактики».
Сравнение сгенерированных из текстовых полей электронной медицинской карты пациента (ЭМК) цифровых профилей с цифровыми профилями клинических рекомендаций позволит избежать ошибок при определении диагнозов, назначении процедур диагностики, лечения и профилактики пациентов.
Проблема: врачи перегружены, неравномерность профессионального уровня врачей
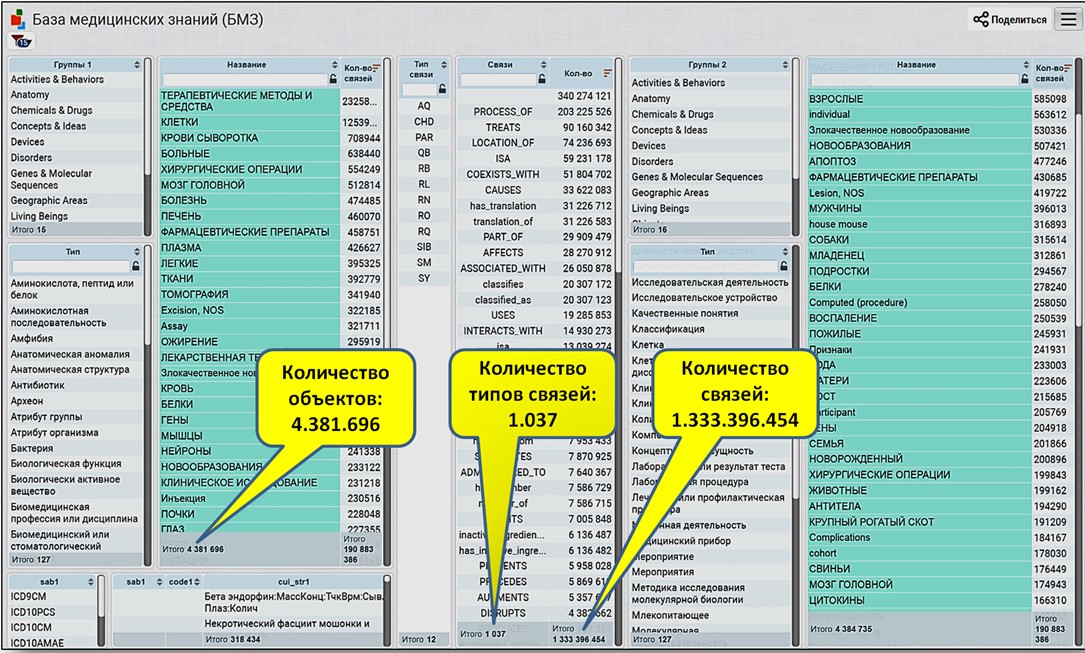
Информационный сервис по отдельным медицинским направлениям (кардиология, урология и т.п.), учитывающий взаимосвязь и взаимозависимость сопутствующих заболеваний, относящихся к различным направлениям. В Базе медицинских знаний (Knowledge Graph) проекта хранится структура, основанная на 150+ российских и международных справочниках, и содержащая 4.4 млн. медицинских сущностей по 100+ типовым группам. Эти сущности объединены в граф, содержащий 1,4 млрд. связей по 950+ типовым группам связей.
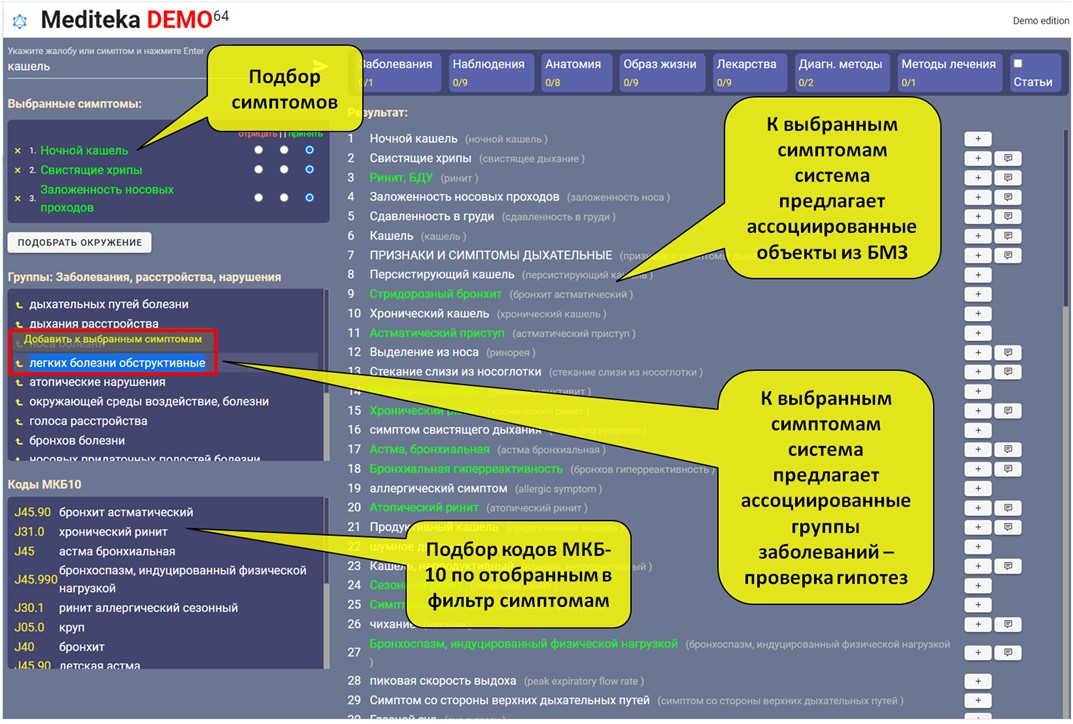
Сервис позволяет производить фильтрацию и рескоринг выдачи результатов из Базы медицинских знаний, соответствующие данному медицинскому направлению.
В отличие от существующих информационно-справочных медицинских систем, предлагающих врачам читать и осмысливать текстовые выдержки из рекомендуемых протоколов лечения и клинических рекомендаций, сервис может предложить врачу:
- По введенным признакам состояния пациента – соответствующие им симптомокомплексы. БМЗ содержит 323 тыс. симптомов, признаков и обнаружений, перевязанных заболеваниями, патологиями и анатомией;
- По предполагаемым диагнозам – сопутствующие диагнозы и осложнения. БМЗ содержит 114 тыс. связанных диагнозов заболеваний и синдромов;
- По предполагаемым диагнозам – необходимые лабораторные, и диагностические процедуры. БМЗ содержит 98 тыс. подобных процедур;
- По предполагаемым диагнозам – необходимые лечебные процедуры. БМЗ содержит 307 тыс. терапевтических и профилактических процедур;
- Лекарственное взаимодействие при различных расстройствах. БМЗ содержит 170 тыс. лекарственных препаратов, химических элементов, а также 1.7 млн. парных взаимодействий (увеличивает /уменьшает воздействие, противопоказан совместное применение и т.п.).

Проблема поддержки научно-исследовательских работ и учебного процесса.
Сервис создания семантических хранилища научных медицинских статей, монографий. Аннотирование медицинских текстов сущностями из Базы медицинских знаний позволяет на хранилищах текстовых документов реализовать не только функции поиска по ключевым словам, но также и функции семантического поиска.
Семантические хранилища, базирующиеся на онтологиях, позволяют гибко подстраивать «на лету» библиографические структуры поиска документов в зависимости от специфических запросов пользователя.
Сервис осуществляет перевод «на-лету» семантически подобранных по запросу пользователя абстрактов англоязычных статей PubMed с выделением в тексте похожих по смыслу запроса сущностей.
Созданный репозиторий семантического хранилища документов медицинской тематики решает проблемы:
- повышения эффективного семантического поиска информации и данных – исследователи;
- повышения эффективности учебного процесса в медицинских вузах и училищах.
ТЕХНОЛОГИЯ
Описание базовой технологии
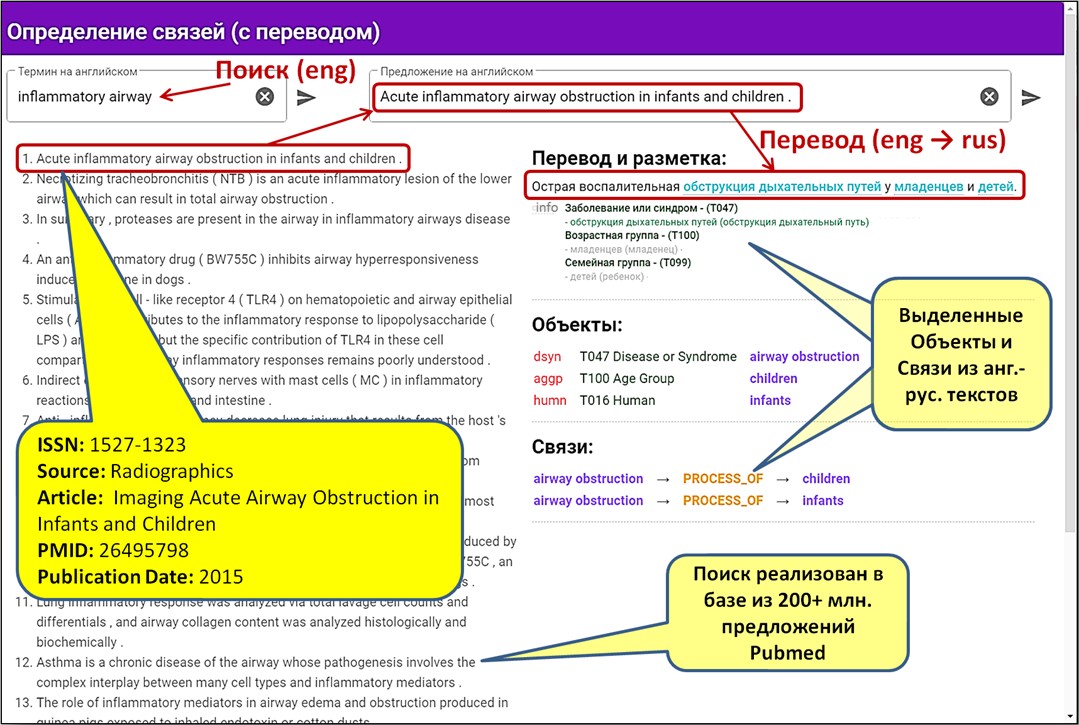
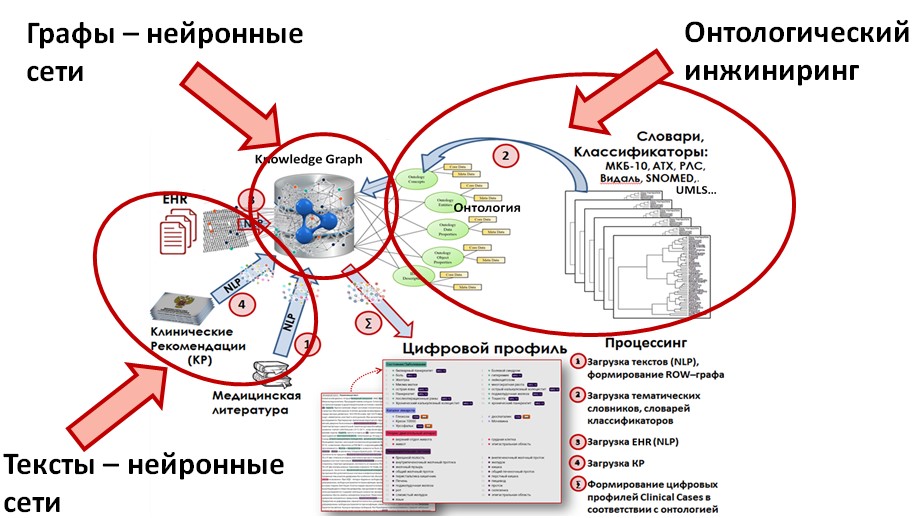
При оцифровке медицинских документов необходимо выделять в текстах и идентифицировать объекты и связи между ними используя объекты онтологической базы медицинских знаний. Это требует наличия технологий:
- Онтологического инжиниринга – необходимо связать в единый граф большое количество российских и международных словарей и справочников;
- Графовой аналитики – необходимо реализовать эффективные функции навигации по графу и графового изоморфизма (поиска в графе похожих подграфов и узлов);
- Функционала обработки естественного языка – выделения в текстах объектов (Name Entity Recognition), выделения связей (Relation Extraction), кластеризации и категоризации объектов и текстов, семантического поиска похожих объектов и текстов.
Проект базируется на Аналитической интеграционной платформе DataMonitor – системе класса «семантический BI/OLAP», (собственная разработка, в реестре отечественного ПО № 5609 от 26.07.2019).
Цифровые профили создаются нейронными сетями, анализирующими медицинские тексты алгоритмами NLP. Нейронные сети натренированы, после извлечения из текстов объектов (Name Entity Recognition, NER), «заглядывать» в онтологический граф (Knowledge Graph) для извлечения и классификации фактов, упомянутых в этом тексте. Факты извлекаются, как семантические тройки «субъект–предикат–объект», моделирующие практически любые отношения между сущностями.
Использование Knowledge Graph для задачи извлечения фактов позволяет избежать огромной работы по ручной разметке медицинских текстов лингвистами и медицинскими экспертами, требуемой при использованию алгоритмов rule-based modeling.
ТРЕБОВАНИЯ
Минимальные системные требования:
- ОЗУ не менее 64Gb*
- SSD - 1Tb*
- операционная система Ubuntu, версии не ниже 18.04*
- СУБД PostgreSQL, версия не ниже 9.6*
* - требования к оборудованию уточняются после согласования технического задания с Заказчиком.